


JSON to CSV in Python
In this tutorial, we will convert multiple nested JSON files to CSV firstly using Python’s inbuilt modules called json and csv using the following steps and then using Python Pandas:-
- First of all we will read-in the JSON file using JSON module.
- Then we will create a list of the data which we want to extract from each JSON file.
- Then we will write the data from these multiple nested JSON file to a CSV file using the CSV Module.
You must note that the we will be converting multiple nested JSON files to a CSV file.
Convert JSON to CSV using inbuilt modules json and csv
Reading-in the JSON file
So, I have a directory called ‘json_to_csv’ which has another directory called ‘descriptions’ in it, which contains multiple large JSON files, which I need to parse and convert to a single CSV. We will be using an inbuilt module called json module.
First, we will check what each JSON file has. Create a Python file call ‘json_to_csv.py’ in the base directory and write the following code:-
import json
from pprint import pprint
# we are using pprint for making the output more readable.
with open('descriptions/ISIC_0000000') as f:
data = json.load(f)
pprint(data)
The output data is in the form of dictionary with keys:- ‘_id’, ‘_modelType’, ‘created’, ‘creator’, ‘dataset’, ‘meta’, ‘name’, ‘notes’, ‘updated’ and few values are further in the form of nested JSON. So, using this tutorial you can easily convert a nested JSON file to a CSV file:-
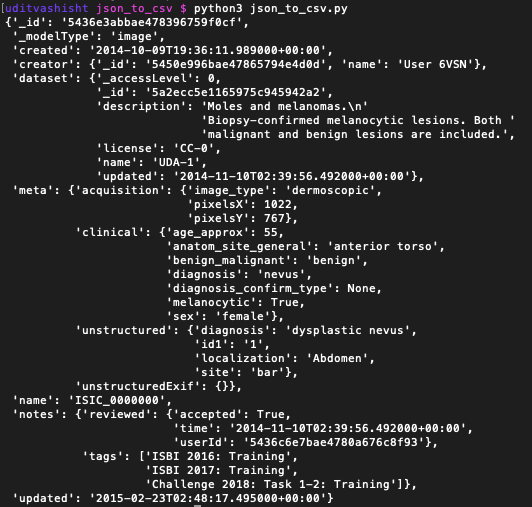
We need to parse the following columns from this nested json file and convert it to csv file:-
_id, _modelType, creator___id, creator__name, dataset___accessLevel, dataset___id, dataset__description, dataset__name, meta__acquisition__image_type, meta__acquisition__pixelsX, meta__acquisition__pixelsY, meta__clinical__age_approx, meta__clinical__benign_malignant, meta__clinical__diagnosis, meta__clinical__diagnosis_confirm_type, meta__clinical__melanocytic, meta__clinical__sex, meta__unstructured__diagnosis, meta__unstructured__race, name
So create an empty ‘output.csv’ file and copy paste the above line as the header in it:-
$ nano output.csv
We will be making it a re-usable script and hence, we will not be doing any hard coding for it. We will use os module to browse through the directories.
First of all, we will skim through the directory ‘descriptions’ and add all the files (filenames) into a list:-
import os
import json
import csv
def get_list_of_json_files():
list_of_files = os.listdir('descriptions')
return list_of_files
Extracting desired data from each nested JSON file to CSV.
Now for each nested JSON file, we will extract the data of the relevant columns e.g. ‘_id’, ‘_modelType’. etc. and append it to a list, which we will later write in to a CSV. We must note that few of these columns are the keys of nested JSON (second level dictionaries) as shown in the pic above. Create the following function:-
def create_list_from_json(jsonfile):
with open(jsonfile) as f:
data = json.load(f)
data_list = [] # create an empty list
# append the items to the list in the same order.
data_list.append(data['_id'])
data_list.append(data['_modelType'])
data_list.append(data['creator']['_id'])
data_list.append(data['creator']['name'])
data_list.append(data['dataset']['_accessLevel'])
data_list.append(data['dataset']['_id'])
data_list.append(data['dataset']['description'])
data_list.append(data['dataset']['name'])
data_list.append(data['meta']['acquisition']['image_type']) #here we are reading in the nested JSON
data_list.append(data['meta']['acquisition']['pixelsX'])
data_list.append(data['meta']['acquisition']['pixelsY'])
data_list.append(data['meta']['clinical']['age_approx'])
data_list.append(data['meta']['clinical']['benign_malignant'])
data_list.append(data['meta']['clinical']['diagnosis'])
data_list.append(data['meta']['clinical']['diagnosis_confirm_type'])
data_list.append(data['meta']['clinical']['melanocytic'])
data_list.append(data['meta']['clinical']['sex'])
data_list.append(data['meta']['unstructured']['diagnosis'])
# In few json files, the race was not there so using KeyError exception to add '' at the place
try:
data_list.append(data['meta']['unstructured']['race'])
except KeyError:
data_list.append("") # will add an empty string in case race is not there.
data_list.append(data['name'])
return data_list
There are few things to note in respect of the above code:-
(i) The Order of the columns must be kept exactly the same as desired in the output.
(ii) For nested JSON file, you will have to call all the keys [key1][key2][key3].
(iii) On scrutiny of the json file, I observed that there are few files which do not contain the ‘[‘meta’][‘unstructured’][‘race’]’ and hence the function threw the KeyError. Use KeyError Exception to give it desired value in the result. I have given it “” (an empty string) as default value.
Note:- We can also use .get() method to avoid key errors the syntax for the same is data.get(key,default_value).
Now, the final task. We will create a function write_csv(), which will open the ‘output.csv’ in append mode and then loop through these multiple nested json files, create the lists of desired data and then write it to the csv file.
Writing data from multiple JSON files to CSV file
def write_csv():
list_of_files = get_list_of_json_files()
for file in list_of_files:
row = create_list_from_json(f'descriptions/{file}') # create the row to be added to csv for each file (json-file)
with open('output.csv', 'a') as c:
writer = csv.writer(c)
writer.writerow(row)
c.close()
And finally, run the script:-
if __name__=="__main__":
write_csv()
We will get the desired CSV file in matter of a second.
Convert JSON to CSV using Pandas
You can easily convert a flat JSON file to CSV using Python Pandas module using the following steps:-
1. We will read the JSON file using json module.
2. Flatten the JSON file using json_normalize module.
3. Convert the JSON file to Pandas Dataframe.
4. Convert Pandas Dataframe to CSV, thus converting the JSON file to CSV.
Installing Pandas
As described above, we will be using Pandas to convert the JSON file to CSV, we will need to install pandas first. If you are new to Pandas, you can check out our tutorial on installing Pandas.
Reading the JSON File
Generally, the JSON files are not in a format of reading them directly to a Pandas Dataframe. Generally, a file of the following format can be converted directly to a pandas dataframe:-
{"Product":{"0":"Desktop Computer","1":"Tablet","2":"iPhone","3":"Laptop"},"Price":{"0":700,"1":250,"2":800,"3":1200}}
But a general JSON file is of the following format :-
{
"fruit": "Apple",
"size": "Large",
"color": "Red"
}
So, let’s read the JSON file
import pandas as pd
import json
with open('example_1.json') as f:
data = json.load(f)
Flattening the JSON file and converting it to Pandas Dataframe
We will use json_normalize() module to flatten the JSON file and converting it to a Pandas Dataframe. Let’s have a look at the Pandas Dataframe.
from pandas.io.json import json_normalize
df = json_normalize(data)
print(df)
# Output
color fruit size
0 Red Apple Large
Converting Pandas Dataframe to a CSV file, thus converting the JSON to CSV.
Finally, we will convert the JSON file to CSV file using Pandas.DataFrame.to_csv() as under:-
df.to_csv('output_u.csv', index=False)
We have used index = False because when we converted our JSON file to a Pandas Dataframe, Pandas automatically gave it the default index. You can know more about Pandas Indexes or watch our video on Pandas Indexes.
Converting a nested JSON file to CSV using Python Pandas
You can also convert a nested JSON file to CSV using Python Pandas’ json_normalize() method. Let’s try to convert the JSON file used in the above example to csv.
import pandas as pd
import json
from pandas.io.json import json_normalize
with open('ISIC_0000000', 'r') as f:
data = json.load(f)
df = json_normalize(data)
print(df.columns)
# Output
Index(['_id', '_modelType', 'created', 'creator._id', 'creator.name',
'dataset._accessLevel', 'dataset._id', 'dataset.description',
'dataset.license', 'dataset.name', 'dataset.updated',
'meta.acquisition.image_type', 'meta.acquisition.pixelsX',
'meta.acquisition.pixelsY', 'meta.clinical.age_approx',
'meta.clinical.anatom_site_general', 'meta.clinical.benign_malignant',
'meta.clinical.diagnosis', 'meta.clinical.diagnosis_confirm_type',
'meta.clinical.melanocytic', 'meta.clinical.sex',
'meta.unstructured.diagnosis', 'meta.unstructured.id1',
'meta.unstructured.localization', 'meta.unstructured.site', 'name',
'notes.reviewed.accepted', 'notes.reviewed.time',
'notes.reviewed.userId', 'notes.tags', 'updated'],
dtype='object')
If you have a look at the columns, Python Pandas has automatically flattened the nested JSON and our Pandas Dataframe contains all the lowest level values (even for the nested JSONs). Now we will drop the columns which we do not need using df.drop()
to_be_dropped = ['created','dataset.license', 'dataset.updated', 'meta.clinical.anatom_site_general', 'meta.unstructured.id1',
'meta.unstructured.localization', 'meta.unstructured.site',
'notes.reviewed.accepted', 'notes.reviewed.time',
'notes.reviewed.userId', 'notes.tags', 'updated' ]
df.drop(columns = to_be_dropped, inplace = True)
And finally, we will be converting the nested JSON to CSV using pandas.DataFrame.to_csv()
df.to_csv('output.csv', index=False)
The complete JSON TO CSV Python code can be downloaded from GITHUB.
We need your support to keep our servers running
If you like our content and want to help us running our servers please contribute here